
Visste du att du kan skapa egna verktyg för ”Geobearbetning” (Processing)?
Ja det går att bygga grafiska modeller, men det går även att skriva verktyg direkt i Python. I detta inlägg så tittar jag på lite grundläggande förutsättningar för att detta skall fungera.
Det går att skriva skriptet i valfri redigerare, men det finns en ganska bra inbyggd i QGIS som jag kommer att använda. Då hamnar dessutom skripten på rätt ställe med en gång. Om du inte gör såhär så skall du se till att skripten hamnar på sökvägen:
.qgis2/processing/scripts
Är det svårt? Om man kan lite Python och kan Googla eventuella problem så, nej! Det är inte speciellt svårt. Det beror naturligtvis på hur avancerade skript man skriver.
Här tänker jag skapa ett som är lite lagom avancerat som raderar kolumner från en tabell i ett vektorlager. Verktyget kan sedan användas fristående eller som en del i en processmodell.

Under ”Skript” finns en samling verktyg/tools där man kan lägga till skript från en fil, men även skapa ett nytt skript.
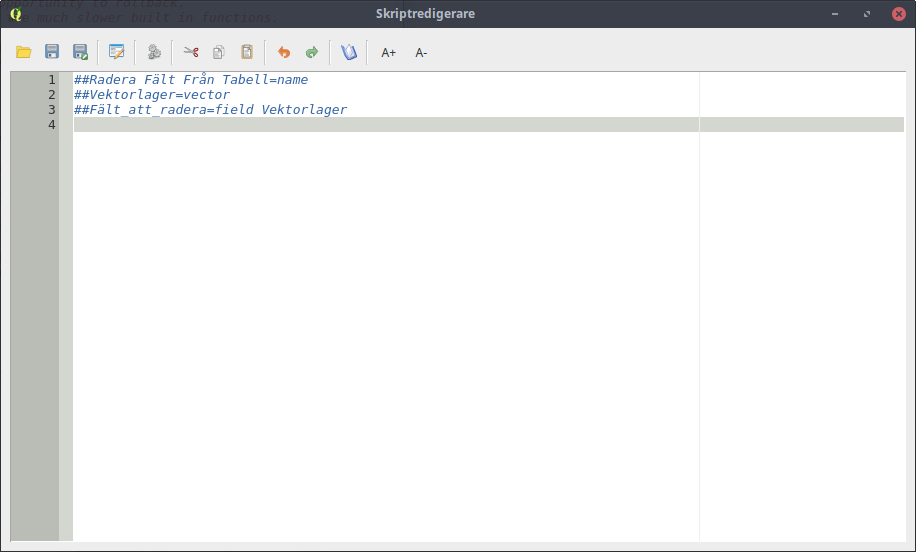
Skripten är ren Python, förutom lite QGIS specifika koder, som ignoreras av en vanlig Python-tolk.
Kommentarer i Python inleds med ”#”, men om man skriver ”##” så är det en signal till QGIS att här finns information om verktyget. I bilden ovan har jag skrivit med svenska tecken, men det är ändrat i resten av koden nedan. Det fungerar nämligen inte alls att använda annat än ren AscII i dessa sammanhang.
Det första jag angett är ett namn på verktyget. Detta kommer att skrivas ut i dialogrutan när man kör verktyget från QGIS. Sedan har jag två ”Input” variabler. Dessa anges först med ett namn (inga mellanslag) följt av ett ”=” och sedan en definition av vilken typ av indata det är.
Det kan vara: raster, vector, table, number, string, multiple raster, multiple vector, field, folder, file, crs, etc.
Några av dessa behöver ytterligare parametrar, exempelvis ”field” behöver en variabel som pekar ut vilket vektorlager som avses.
Du kan läsa mer om detta på https://docs.qgis.org/2.6/en/docs/user_manual/processing/scripts.html.
Vill man ha en ”Output” så sätter man in ett ”output ” framför definitionen. Det är inte alla typer av definitioner som kan användas som ”output” men mer om det på länken ovan. Jag kommer inte att behöva en output för mitt skript.
Som vanligt i Python så behöver man importera en del klasser som man använder. Jag väljer att importera de jag använder explicit i enlighet med Python3, även om det inte behövs för Python2.
I övrigt när jag skriver skriptet så hoppar jag mellan att redigera skriptet och att testa i Pythonkonsolen i QGIS. Det är inte riktigt samma sak, då Pythonkonsolen redan har alla klasser inlästa, men för att testa funktioner och att hitta vilken klass ett kommando finns i så är det perfekt.
##Radera Falt Fran Tabell=name
##Vektorlager=vector
##Falt_att_radera=field Vektorlager
from qgis.core import QgsVectorLayer, QgsVectorDataProvider, QgsMapLayerRegistry, QgsMessageLog
QgsMessageLog.logMessage("Lager att bearbeta: %s" % Vektorlager, "Radera")
QgsMessageLog.logMessage("Falt att radera: %s" % Falt_att_radera, "Radera")
vectorLayer = QgsVectorLayer(Vektorlager, 'TEMP', "ogr")
vectorLayer.isValid()
QgsMessageLog.logMessage("Hamtar faltindex for: %s" % Falt_att_radera, "Radera")
fieldID = vectorLayer.fieldNameIndex(Falt_att_radera)
QgsMessageLog.logMessage("Raderar Falt", "Radera")
vectorLayer.dataProvider().deleteAttributes([fieldID])
vectorLayer.updateFields()
QgsMessageLog.logMessage("Laser om tabellen...", "Radera")
QgsMapLayerRegistry.instance().reloadAllLayers()
Jag har valt att lägga till flera rader som inleds med ”QgsMessageLog”, vilket skriver en rad till QGIS loggfönstret. Detta är mest för debugging och du kan enkelt hoppa över dessa rader.
Det första egentliga som sker är att en variabel (vectorLayer) definieras som ett QGIS vektorlager, men den sökväg som angetts i ”input” för Vektorlager. Det görs även en kontroll för att se att det är ett giltigt vektorlager.
Att radera fält i en tabell görs med en indexsiffra, och för att lagra denna siffra använder jag variabeln fieldID.
Hela fältet raderas med ”deleteAttributes” raden, som följs av ett kommando för att uppdatera fälten. Detta slår dock inte igenom i lagerlistan i QGIS, så för att även detta skall uppdateras så använder jag ”.reloadAllLayers()”.

När man kör skriptet så är det bara att välja ett lager och ett fält att radera. Det går att köra ”satsvis” i en batch-körning, men då behöver man fylla i lite mera själv.
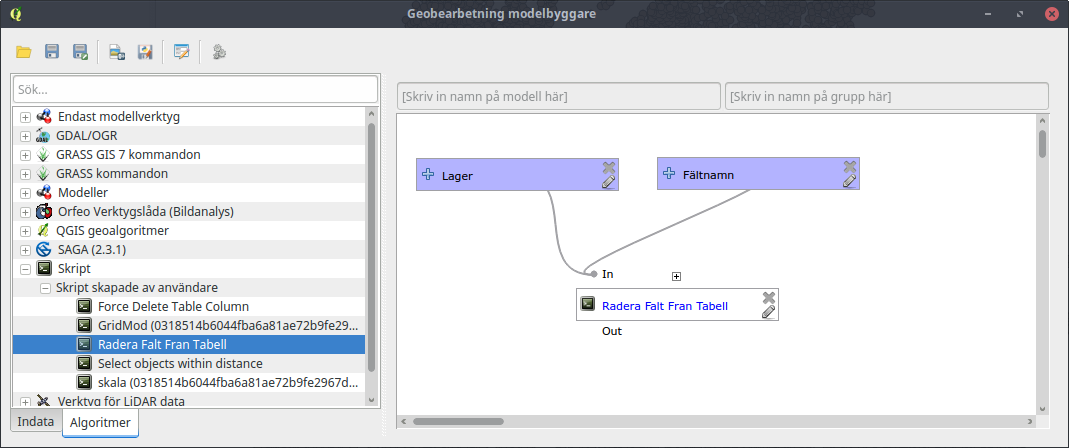
Det går även att använda skriptet i den grafiska modellbyggaren, precis som om det vore vilket verktyg som helst.
Varför har jag nu gjort det här verktyget då?
På QGIS Sveriges ”Slack” kanal så ställdes frågan hur man bäst raderar fält från en tabell med väldigt mycket data. Det normala är att man öppnar attributtabellen, startar redigeringsläge, klickar på ta bort kolumner, väljer kolumner att radera och bekräftar! Inget konstigt med det. Problemet är att denna metod läser in hela tabellen flera gånger under processen och är det då väldigt mycket data så tar det låååång tid, med risk att QGIS hänger sig.
Detta var anledningen till att jag började leta efter bättre alternativ och i slutändan skapade detta skript.
Just det här problemet kan man dock lösa betydligt smidigare i QGIS…

I lageregenskaperna, på ”Fält” fliken, kan man också starta redigeringsläget, markera de fält man vill radera och klicka på ”Radera fält”. Allt utan att behöva läsa om tabellen, så på detta sätt är raderingen av fälten omedelbar (”blink and you missed it!”).